

There are probably definitely several articles out there which cover the SQL implementation of the Nested Set Model, aka “modified preorder tree traversal” (which is more the name of the algorithm by which you traverse the tree, rather than the structure itself). But I found it interesting enough, and more importantly, applicable enough to my job experience, that I feel it deserves some treatment. Not the basic “how to”, but more an example of a particular operation and a specific pitfall to avoid. (Jump straight to the example diagrams.)
Now, we’re not going to debate about whether this model is “the best” representation of hierarchical data in an RDBMS (some argue that Closure Tables, aka “Ancestor Tables“, or some kind of hybrid approach is better, and I’d probably agree). The fact is, sometimes (read: almost always) as a DBA/DBDev, you’re “stuck with” an existing database in a legacy application environment that you pretty much can’t change — or if you can, changes need to be small, incremental, and non-disruptive.
Okay, with that disclaimer out of the way, let’s dive in. First things first:
The #1 rule of implementing the Nested Set Model is: FAST READs.
I can’t stress that enough. Fast SELECTs. Everything else pales in comparison. In other words, we don’t care how long and painful and slow write operations are against this table (updates, inserts, deletes), as long as our SELECTs remain super speedy. If that is not your use-case, consider a different model.
The #2 rule of the Nested Set Model is: see #1
Moving on…
The #3 rule is: encapsulate tree operations to maintain its integrity & structure.
Put another way, the #3 rule is that you should always operate on the tree (CrUD ops) using stored-procedures and/or triggers that encapsulate all the nitty-gritty details of maintaining the correct position values during said insert/update/delete operations. Of course, somebody is responsible for writing those stored-procs. Any volunteers? Easy now, don’t raise your hands all at once! Generally, this responsibility falls to the DBA(s) or DBDev(s).
The problem at-hand, in my current situation, was that of “moving a sub-tree”, i.e. taking a node and all its descendants, and moving it to place it under another “parent” node. In some models, and/or in some languages, this is a simple recursive operation. However, SQL is not spectacular at recursion — after all, we’re working in a relational engine — so let’s try to play to its strengths:
namely, SET-BASED operations!
A previous DBDev had written a stored-proc for just such an operation. However, as (somewhat) expected, it was horribly slow, to the tune of hours of run-time. This is not acceptable, even given the #1 rule stated above.
Well it turns out that most of it was pretty efficient, but the last step, in which they attempted to “fix” the left/right values in the entire table “just to make sure we didn’t leave any gaps“, was, frankly, quite silly. Because the only “gaps” you create are created by the previous steps in the proc, and you know exactly how big that gap is (the width of the subtree you’re moving), and where it is, so you should be able to target that specific area of the tree and close the gap more intelligently, using some simple math. (addition and subtraction — the simplest math there is!)
Doing that improved the performance of the whole proc by a factor of 10. That’s huge. Or, “yuuuuge“.
So let’s get specific. As you’ll see from my diagrams, the model actually is a hybrid, combining an Adjacency List (each record knows its “parent”) with a Nested Set (each record has a “left” & “right” position value). We do this for two big reasons. First, having the parent relationship along with the position values makes all that nasty book-keeping (rule #3) a bit easier to manage (and to check our work). And second, because, conveniently, we can store the data from both models in one table.
First, we have our tree of Cats.

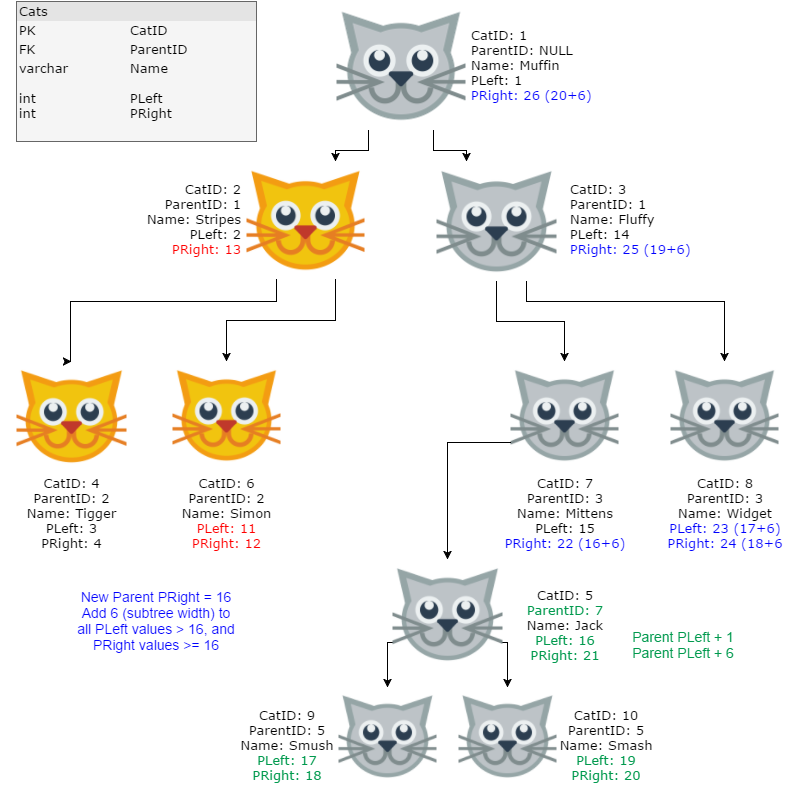
CatTreeNow, we want to move Jack & his children to become descendants of Mittens (Jack being the child, Smush & Smash being grandchildren). So we start by “making a gap” of the subtree’s “width” (6, the distance between Jack’s PLeft and PRight inclusive of end-points). We add that amount to all PRight values >= Mittens’ original PRight, and add it to all PLeft values > Mittens’ PRight — see the blue #s in diagram below, and code here:
UPDATE Cats
SET PLeft = (CASE WHEN PLeft > @NewParentRight
THEN PLeft + @SubtreeSize
ELSE PLeft END)
, PRight = (CASE WHEN PRight >= @NewParentRight
THEN PRight + @SubtreeSize
ELSE PRight END)
WHERE PRight >= @NewParentRight
The red values haven’t changed (yet) but are now wrong, so we’ll have to fix them next. And of course the green values are the moved subtree’s new positions based on the new parent’s (Mittens) PLeft.
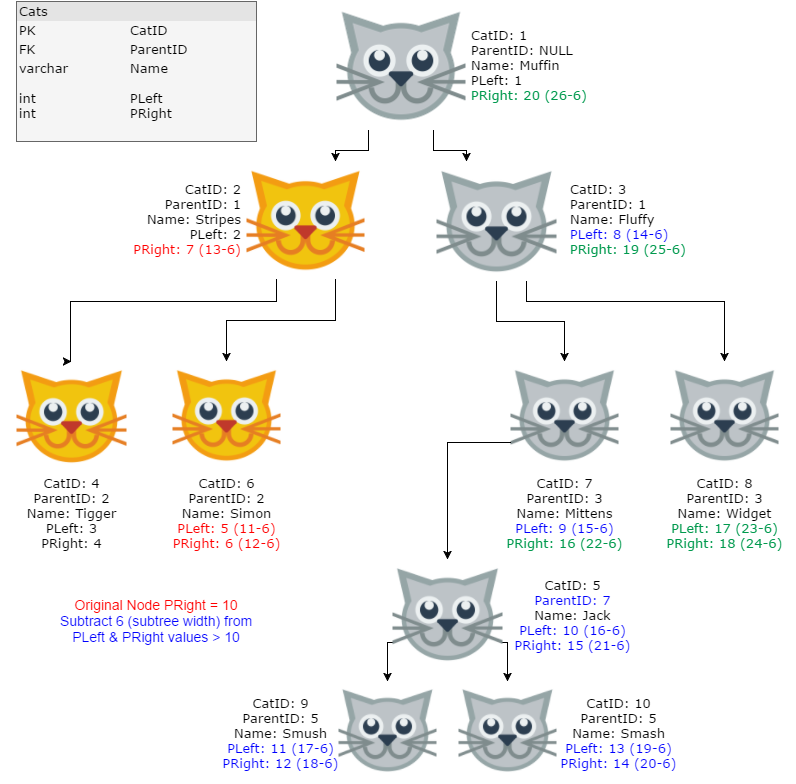
Finally, now that we’ve moved Jack & his children under Mittens, we need to “close the gaps” that we created at first, to make sure that the tree’s position values remain contiguous. This isn’t as difficult as it sounds: if we’ve stored Jack’s original PRight value (10), we can use that as a cutoff to subtract the subtree width from higher position values and intelligently (and quickly) close the gaps we created before. Again, code & diagram:
--Notice this looks very similar to the previous
--code snippet! (We're basically doing the reverse)
UPDATE Cats
SET PLeft = (CASE WHEN PLeft > @SubtreeOldRight
THEN PLeft - @SubtreeSize
ELSE PLeft END)
, PRight = (CASE WHEN PRight >= @SubtreeOldRight
THEN PRight - @SubtreeSize
ELSE PRight END)
WHERE PRight >= @SubtreeOldRight
SQL-wise, this should translate pretty well. I’ve posted the setup and stored-proc scripts to GitHub, so the distinguishing reader can review and offer feedback. In theory, there’s probably a way to exclude the green reverted values from the first pass operation (gap-making) so that we don’t have to revert them (at gap-closing), but again, since we’re doing SQL set-based operations, it seems hardly worth the effort — i.e. the potential speed gain would be outweighed by the logical/maintenance complexity.
So what’s the lesson here? Well hopefully, if you’re “stuck with” a SQL DB with a Nested Set Model table containing a hierarchical tree of data, you don’t have to completely re-invent the wheel and write your CrUD ops from scratch. But if your predecessors didn’t plan for certain kinds of operations, and this “move a subtree to a new parent” happens to be one of those, this should help you (re)implement it efficiently.
I’d love to get some feedback on this. Let me know if I’ve missed anything conceptually, if there are better ways or methods to doing any of this, or any other tips & tricks that folks might have for dealing with such data. Leave me a comment!
[footnote 1]
The root of the problem, in this case, was simply taking the code from a slideshare presentation and copy-pasting it into the routine without analyzing its effectiveness and efficiency. It proposed re-calculating the position values after a move, across the entire tree, by using a triple-cartesian-product (or cross-join) to “get the count of nodes to the left/right of each node” for every node, which should sound dirty even as you say it silently in your head, let alone attempt to write it in query form!
[footnote 2]
There’s a 3rd model that we could consider storing in the same table, called “Enumerated Path” or “Materialized Path” or “Breadcrumbs”, which may look good on paper and to your human eyeballs, but breaks down spectacularly when you start talking performance and scale — but to be fair, so do most of these models, eventually, in one way or another, which is why we’ve invented fantastic alternative technologies to address these problems… and frankly, if you’re using all 3 models at once, you’re #DoingItWrong, creating a veritable maintenance nightmare for yourself and everyone around you. Note that the elusive 4th model, the Ancestor Table, requires (as the name would imply) another table — not an argument for or against anything, just an observation.
PS: Happy 2017!

See also http://stackoverflow.com/questions/4048151/
LikeLike